-
[08.12] Day9 - 'Sequential Models(RNN + Transformer)'네이버 부스트캠프 AI Tech 2기 2021. 8. 13. 20:03728x90반응형
RNN
[수업 내용]
강사 : 최성준 조교수님
Sequential Model
: 말, 비디오, 모션 등등 모든 것이 Sequential Data이다.
어려움은? : 얻고 싶은 것이 하나의 라벨(클래스)인데, 시퀀셜 데이터는 정의상 길이가 정해지지 않는다. 그래서 정적인 CNN이나 MLP을 사용할 수 없다. 몇개의 이미지, 몇개의 음절들이 들어올지 모르기 때문이다.

- Markov Model(Markov 가정을 가진다. → 나의 현재는 직전 과거에만 Dependent하다)
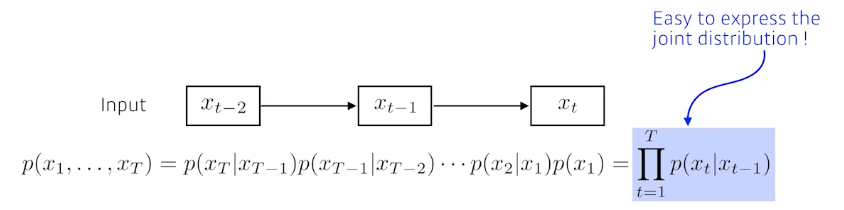
- Latent Autoregressive Model(과거 많은 정보를 고려해야하는데 Markov는 그렇지 못하고 손실이 많았다. 그래서 Latent는 과거 정보를 요약하고 있다.)

→ RNN은 MLP와 거의 똑같은데, 나 자신으로 돌아오는 것이 더 있다.
RNN 구조

실제론 왼쪽 그림과 같이 하나의 셀을 통해서 현재 time stamp T에 대해서 계산되고 다시 들어오면, T+1 번째에 적용되는 것이다. 이를 시간 순서로 풀어서 보여주는 그림이 오른쪽 그림이다.
중요한 점 : Recurrent로 되어 있는 구조를 길게 풀면, 입력이 굉장히 많은 Fully-Connected 구조로 보여질 수 있다.
단점 : Long Term Dependency(장기 의존성 문제)

→ 꽤 멀리 있는 정보는 손실이 되는 문제
RNN 모델의 수식


W와 U는 가중치이고 이전에 있는 정보 h와 현재 input x가 결합되는 형태이다.
이때 계산은 중첩되면서 Vanishing, Exploding Gradient 문제가 발생한다.(0~1사이 값이 계속적으로 곱해지기 때문에)
activation function → tanh를 사용하는 이유
Sigmoid : Vanishing Problem
ReLU : Exploding Gradient Problem
LSTM 구조를 뜯어보자
전체적인 구조

- Xt는 Input이다. ht는 output이다.(hidden state)
- 이전에 들어오는 정보가 Previous Cell State로 들어온다.
- 이전에 Hidden State도 들어온다. (Previous Hidden State)
- Forget Gate
- Input Gate
- Output Gate

Core Idea - Gate(어떤 정보를 넣을지 뺄지를 정하는 역할)

Forget Gate
: 어떤 정보를 버릴지
- 현재 정보 + 이전 Hidden State(얘를 어떤 것을 버릴지 말지)를 가지고 통과한다.[it]

Input Gate
: 현재 들어온 것을 Cell State에 무조건 올리는 것이 아니라, 어떤 정보를 올릴지
- 이전 Hidden State + 현재 정보(얘를 어떤 것을 추가하고 버릴지)를 가지고 통과한다.[it]
C 틸다 - 우리가 올릴 정보. 를 알아야 한다. tanh를 통해서 [-1,1]까지 정교화 된 형태를 만든다. 현재 정보와 이전 출력 값을 통해 만든 Cell State 예비군이다.

Update Cell
: 이전의 정보와 현재의 정보를 적절히 섞어서 현재 Cell을 업데이트 한다.

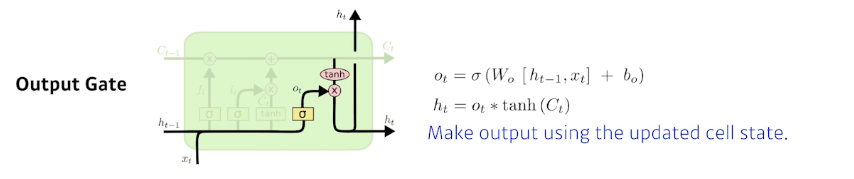
Output Gate
: 한번더 조작을 해서 어떤 값을 밖으로 내보낼지 정하는 게이트
GRU(Gated Recurrent Unit)

- Gate 가 2개로 simple하다(Reset, Update Gate)
- Cell State가 없고, 바로 Hidden State로 나간다.
⇒ 요즘에는 얘네들도 많이 잘 안쓰고 Transformer로 넘어가는 추세이다.
Transformer
→ Sequential Model을 다루는 방법론 중 하나
왜 등장했나? 예시를 보자.

이런 다양한 형태의 문장으로 들어오는 것이 현실.(순서가 바뀌거나 중간에 단어가 빠진 경우 등등)
이런 것들을 해결하기 위해서 Transformer가 등장했다.
Transformer is the first sequence transduction model based entirely on attention.
→ RNN은 반복적으로 돌아가는 구조였는데, Transformer는 attention이라는 구조를 활용해서 시퀀셜 모델을 만들어 냈다.
어떤 문장이 주어지면, 그것을 영어로 바꾸는 형태 (Sequence To Sequence)


- 입력 시퀀스와 출력 시퀀스가 다를 수 있다.
- 입력 시퀀스의 도메인과 출력 시퀀스의 도메인이 다를 수 있다.
- 모델은 하나!
- 동일한 구조를 가지지만, 네트워크 파라미터가 다르게 학습되는 Encoder, Decoder가 쌓여있는 구조
핵심 내용
- N개의 단어가 Encoder에서 어떻게 한번에 처리되나?
- Encoder와 Decoder사이에 어떤 정보를 주고 받나?
- Decoder가 어떻게 Generation할 수 있는가?
Encoder
Self-Attention

하나의 Encoder는 Self-Attention과 Feed Forward NN을 거친다.
- Self-Attention이 중요한 부분과정3개의 단어가 있을때, 각각의 단어에 따라서 모든 단어들과의 Dependency를 구하게 되고, 이는 새로운 벡터로 표현이 된다. 그 후, 각각 독립적인 Feed Forward를 통과해서 나가게 된다. 3가지 Vector를 각각 단어마다 구해야 한다.
- Query 벡터
- Keys 벡터
- Values 벡터
각각의 단어마다 3가지 벡터를 구해 놓는다.: 내가 인코딩하고자 하는 단어의 query vector와 나머지 모든 단어의 key vector를 모두 구해서 내적을 진행한다. → 단어마다 다른 단어들과 유사도를 띄는가를 알 수 있다.이게 i 번째 단어와 다른 단어들과 얼마나 interaction해야할지 알아서 학습하게 한다. 이것이 바로 Attention의 역할이다.
 최종적으로 내가 직접적으로 사용할 값은, 단어 Embedding에서 나오는 Value들의 Weight들의 Sum이다.
최종적으로 내가 직접적으로 사용할 값은, 단어 Embedding에서 나오는 Value들의 Weight들의 Sum이다.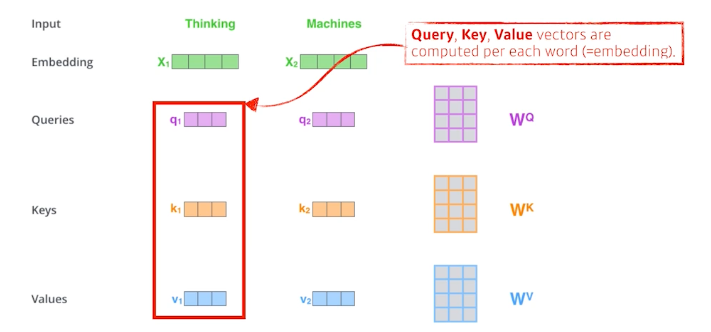 Input이 고정되면, 출력도 고정이 된다. Transformer는 하나의 input이 고정되더라도 내가 인코딩 하려는 단어들에 따라서 인코딩 값이 달라지게 된다.(Flexible 하다)
Input이 고정되면, 출력도 고정이 된다. Transformer는 하나의 input이 고정되더라도 내가 인코딩 하려는 단어들에 따라서 인코딩 값이 달라지게 된다.(Flexible 하다)
- 왜 이게 잘 될까?

- → Tinking은 자기 자신과 관계는 0.88이고 Machine과의 연관성은 0.12이다.
- Score 벡터를 Normalize 해준다. 그 다음 Softmax 함수를 취해주면서 sum to 1이 되도록 한다.

- 그 다음 Score벡터를 계산한다.
- 이제 'Thinking'이라는 단어를 Encoding해보자.
- (Query Vector 차원 == Key Vector 차원)

- 계산 과정
- 즉, 아래 예시에서 it 이라는 단어가 다른 모든 단어들과의 관계성을 따져서 어떤 단어와 가장 의존성이 높은지 학습하게 되는 것이 Self-Attention이다.
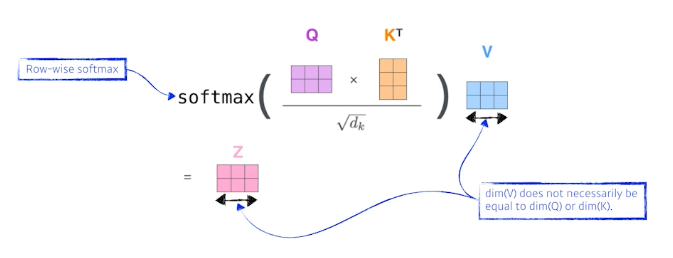
- 각 단어마다 특정 수를 통해 벡터로 표현할 수 있다.
Multi-Head Attention
: 1개의 Embedding Vector에 대해서 Q,K,V 를 여러개를 만든다. N개의 attention을 반복하고 N개의 encoding vector들이 나오게 된다.
(주의. 입력과 출력 차원이 같아야 한다.)

- 입력 임베딩 벡터를 넣고
- 8개의 head로 나눠버리고 계산을 진행한다.
- Attention을 각각 계산한다.(Q/V/K) matrix를 통해서
- 나온 벡터들을 이어 붙힌다. 그리고 W matrix와 곱을 통해서 output layer를 구하게 된다.
positional encoding → 주어진 입력에 어떤 값을 더한다.

생각해 볼것. Encoder가 왜 input order에 대해 독립적으로 각 단어에 인코딩 되는건가?
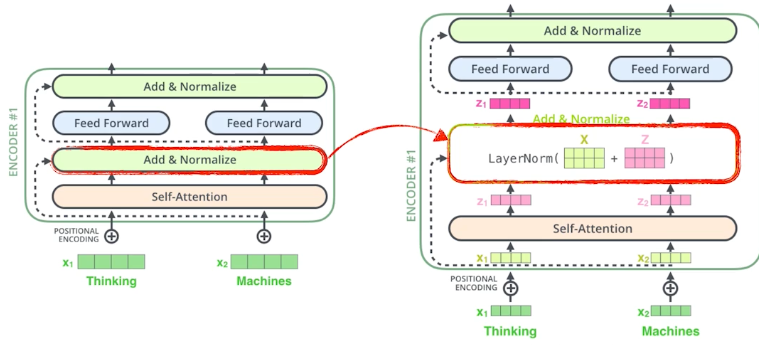
과정 : self-attention → Add&Normalize → Feed Forard → Add&Normalize (repeat)
Decoder
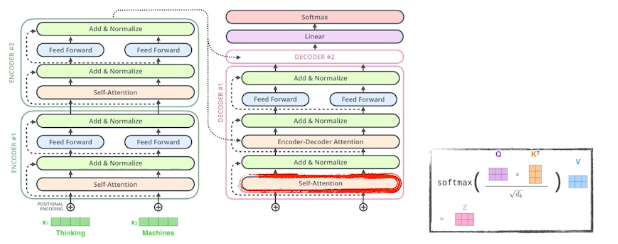
Encoder에서 나온 정보를 통해서 Encoder-Decorder Attention'으로 적용이 된다.
→ 'Encoder-Decorder Attention' layer works like multi-headed Self-Attention, except it creates its Queries matrix from the layer below it, and takes the Keys and Values from the encoder stack.
마지막 레이어
: 단어들의 분포를 만들어서 매번 sampling 하는 식으로 동작한다.

CV에서 사용하는 Attention
DALL·E: Creating Images from Text
DALL·E: Creating Images from Text
We’ve trained a neural network called DALL·E that creates images from text captions for a wide range of concepts expressible in natural language.
openai.com
[피어 세션]
- Attention 모델에 대해서 블로그를 하나 찾고 이를 이야기 했다.
[수업 회고]
- Sequence 모델 같은 경우 원래 관심있는 분야라 더 집중이 잘 된 것 같다.
- Transformer 모델이 지금은 주를 이루고 있기 때문에 이와 관련된 논문을 읽어봐야겠다.
- 그전에 Attention모델이 어떤식으로 흐르는지 방법론과 구조를 이해했다.
- Q, K, V 3가지에 대한 각각의 의미보다는 왜 이런 구조로 처음에 생각해냈는지 궁금하다
반응형'네이버 부스트캠프 AI Tech 2기' 카테고리의 다른 글
[08.10 Special 강의] 📊 기본적인 차트 활용 (0) 2021.08.21 [08.13] Day10 - 'Generative Models'💫 (0) 2021.08.13 [08.11] Day8 - 'CNN(Convolution Neural Network)' (0) 2021.08.13 [08.10] Day7 - '🏃Optimization' (0) 2021.08.13 [08.09 Special 강의] Introduction to Visualization 🤓 (0) 2021.08.13