-
[08.20] Day14 - 🔥 'PyTorch 활용'네이버 부스트캠프 AI Tech 2기 2021. 8. 21. 19:49728x90반응형
[PyTorch] 활용하기
[수업 내용]
강사 : 최성철 교수님
Multi-GPU 학습
오늘날 딥러닝은 엄청난 데이터와의 싸움이다.

어떻게 GPU를 다룰 것인가? 여러 장의 GPU를 다루고 우리가 원하는 목표를 이룰 수 있을까?
→ 보통 2장 이상 있을 때, 멀티 GPU라고 함.
개념
- Single vs Multi
- 한개의 GPU, 여러개 GPU를 쓰는 경우
- GPU vs Node
- Node → 한대의 컴퓨터. 를 의미한다. 1대의 Node(컴퓨터)안에 있는 1개의 GPU를 쓴다.
- Single Node Single GPU
- Single Node Multi GPU
- Multi Node Multi GPU
NVIDIA 에서는 조금더 GPU를 잘 사용해서 학습할 수 있도록 연구를 하고 있다(TensorRT 8.0 등)
Multi GPU를 사용하는 2가지 방법
- 모델을 병렬화(ex. AlexNet)
- 모델 병렬화의 문제위에서 보는 것처럼 병렬화를 진행하면, 병렬화의 의미가 없다.


-
self.seq1 = nn.Sequntial(self.conv1, self.bn1, self.relu, self.maxpool, self.layer1, self.layer2).to('cuda:0') self.seq2 = nn.Sequntial(self.layer3, self.layer4, self.avgpool).to('cuda:1') #각각 모델을 cuda 마다 할당한다. self.fc.to('cuda:1') - 그래서 아래 처럼, 파이프라인을 만들어서 처리가 병렬적으로 진행되어야 한다. → 중요한 이슈 중 하나!
- : 연결된 여러개의 모델을 적절히 나눠서 GPU를 할당한다.
- 데이터를 나눠 병렬화데이터를 나눠 GPU에 할당 후 결과의 평균을 취하는 방법
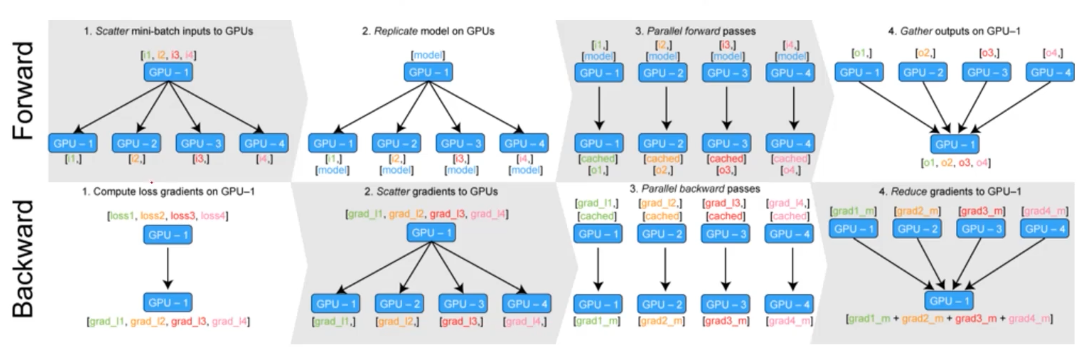
- DataParallel→ GPU 사용 불균형 문제 발생, Batch 사이즈 감소(한 GPU가 병목), GIL
- : 단순히 데이터를 분배한 후 평균을 취한다.
- DistributedDataParallel→ 기본적으로 DataParallel로 하나 개별적으로 연산의 평균을 낸다.
-
#DataParallel parallel_model = torch.nn.DataParallel(model) #DistributedDataParallel #1. Sampler 만들기 train_sampler = torch.utils.data.distributed.DistributedSampler(train_data) shuffle = False pin_memory = True #메모리에 데이터를 바로바로 올릴 수 있도록 절차를 간소하게 저장하는 방식 trainloader = torch.utils.data.DataLoader(train_data, batch_size=20,shuffle=shuffle, pin_memory=True, num_workers = 3 /*Cpu개수*/, sampler=train_sampler) - : 각 CPU마다 프로세스를 생성하여 개별 GPU에 할당한다.
- PyTorch 에서는 2가지 방법을 제공한다.
- minibatch 수식과 유사한데 한번에 여러 GPU에서 수행한다.
- : 데이터 Batch 만큼 GPU를 할당해서 학습을 진행한다.
하이퍼 파라미터 튜닝(Hyperparameter Tuning)
: 학습할 때, 사람이 직접 지정해 주어야하는 파라미터들
(ex. learning_rate 같은 것들)
예전에는 수작업으로 진행했지만, 최근에는 좋은 도구들이 많이 나왔다.
크게 성능을 올리는 3가지 방법
- 모델을 바꾼다.(CV-ResNet, NLP- Transformer 등등 정해진 좋은 모델이 있다.)
- 데이터를 바꾼다.(기존 데이터를 확인, 새로운 데이터를 추가) → 가장 중요하다)
- 하이퍼 파라미터 튜닝(생각보다 큰 역할은 아니지만 끝날 때까지 끝난 것이 아니다.)
하이퍼 파라미터 종류
: learning rate, 모델의 Size, Optimizer 등등. 모델 스스로 학습하지 않는 값을 사람이 지정한다.
하이퍼 파라미터에 의해 값이 크게 좌우 될 대도 있지만 요즘은 그닥? 이라고 한다.
기본적인 방법
- Grid Search vs Random Search

- 베이지안 기법
- (BOHB 논문)
여러가지 도구
Ray(가장 대표적인 도구)
: multi-node multi process 지원 모듈
ML/DL 병렬 처리를 위해 개발된 모듈이다.
기본적으로 현재의 분산병렬 ML/DL 모듈의 표준이다.
하이퍼 파라미터 Search를 위한 다양한 모듈을 제공한다.
!pip install ray config = { "l1" : tune.sample_form(lambda _: 2 ** np.random.randint(2,9)), "l2" : tune.sample_from(lambda _: 2 ** np.random.randint(2,9)), "lr" : tune.loguniform(1e-4, 1e-1), "batch_size" : tune.choice([2,4,,8,16]) } #config에 search space를 지정한다. scheduler = ASHAScheduler( metric = "loss", mode = "min", max_t = max_num_epochs, grace_period = 1, reduction_factor = 2) #학습 스케줄링 알고리즘 정의 reporter = CLIReporter( metric_columns = ["loss", "accuracy", "training_iteration"]) #결과 출력 양식 지정 result = tune.run( partial(train_cifar, data_dir = data_dir), resources_per_trial = {"cpu" : 2, "gpu" : gpus_per_trial}, config = config, num_samples = num_samples, scheduler=scheduler, progress_reporter = reporter) #병렬 처리 양식으로 학습을 진행한다.Troubleshooting
: 학습을 진행하는 동안 부딪칠 여러가지 문제들!!
- Out of Memory [공포의 단어😱]어디서 발생했는지... 알기 어렵다. (Where?)메모리의 이전 상황의 파악이 어렵다.
- 해결법
- Batch Size를 줄인다 → GPU clean → Run
- Error Backtracking 이 이상한데로 간다.
- 왜 발생했는지 알기가 어렵다. (Why?)
- GPU 현재 상태부터 파악하자.Colab은 환경에서 GPU 상태를 보여주기 편하다.
!pip install GPUtil import GPUtil GPUtil.showUtilization() - iter 마다 메모리가 늘어나는지 확인한다.
- GPUtil 사용하기. NVIDIA-smi 처럼 GPU 상태를 보여주는 모듈
- Empty_cache() 써보기가용 메모리를 확보reset 대신 쓰기 좋은 함수
-
from GPUtil import showUtilization as gpu_usage gpu_usage() #Gpu Usage 초기화 tensorList = [] for x in range(10): tensorList.append(torch.randn(100000000, 10).cuda()) del tensorList #삭제 gpu_usage() torch.cuda.empty_cache() #캐시 비우기, 학습 전에 넣어주는 것도 괜춘하다. gpu_usage() - del 과는 구분이 필요하다.
- 사용되지 않는 GPU 상 Cache 를 정리한다.
- trainning loop 에 tensor로 축적 되는 변수는 확인한다.
- 그래서 1d tensor는 python 기본 객체로 변환해서 처리한다.
- tensor 변수는 GPU 상에 메모리 사용한다.
- del 명령어를 적절히 사용한다.
- Python 메모리 배치 특성상 loop이 끝나도 메모리를 차지한다. 그래서 필요없는 변수는 적절히 메모리에서 제거해 주어야 한다.
- 가능한 Batch 사이즈 실험해보기
- 학습시 OOM이 발생했다면 batch 사이즈를 1로 해서 실험해보기
-
OOM = False try: run_model(batch_size) except RuntimeError: #Out of Memory OOM = True
- torch.no_grad() 사용하기
- 추론 시점에서는 torch.no_grad() 구문을 사용한다. backward pass로 인해서 쌓이는 메모리에서 자유롭다.
-
with torch.no_grad(): for data, target in test_loater: ...
- 기타 여러 에러
- OOM 말고도 유사 에러들이 발생한다.
- CUDNN_STATUS_NOT_INIT : GPU 설치에러
- device-side-assert : OOM 일종
- 그 외 더 +
- colab에서 너무 큰 사이즈는 실행하지 말자(Linear, CNN, LSTM)
- CNN의 대부분 에러는 크기가 안 맞아서 생기는 경우
- tensor의 float precision을 16bit 로 줄일 수 있음
[수업 회고]
- 이전 경험했던 모델의 하이퍼 파라미터는 수작업으로 계속 바꾸어 주었다. (사실 그렇게 성능에 영향을 주지 않을 것이라고 생각했다.)
- 그래도 Ray라는 하이퍼파라미터 조정하는 tool이 있다는 사실을 처음 알았고, 딥러닝 모델을 만들때, 하이퍼파라미터 튜닝시 자동화할 수 있는 기능을 넣어봐야겠다.
반응형'네이버 부스트캠프 AI Tech 2기' 카테고리의 다른 글
[08.23 P Stage Day1] - 🚀 Competition with AI Stages! 출발 (0) 2021.08.28 [08.20 Special 강의] 📈 차트의 요소 (0) 2021.08.22 [08.19] Day13 - 👏 'PyTorch 구조2' (0) 2021.08.21 [08.18] Day12 - 👍 'PyTorch 구조' (0) 2021.08.21 [08.17] Day11 - 👊 'PyTorch 기본' (0) 2021.08.21