[08.11] Day8 - 'CNN(Convolution Neural Network)'
CNN
[수업 내용]
강사 : 최성준 조교수님
Convolution 이란?
: f, g 두 함수를 잘 섞어주는 Operator 로 정의할 수 있다.

Convolution 연산 과정
→ 도장 찍는 느낌! (element wise 곱의 합)

의미 : 해당 이미지를 적용하고자 하는 filter를 통해서 찍어준다.
일반적인 이미지는 RGB로 되어 있기 때문에, 3개의 channel을 가지게 된다.)

- 4개의 filter(kernel)을 가지고 Output도 4개가 적용된 것들의 모임으로 구해진다.

- 32323 짜리 이미지를 28284를 얻기 위해서 따져줘야 할 것들이 있다.또한, 하나의 Convolution 연산을 거친 후, Non-linear Function인 Relu함수가 적용이 된 것을 볼 수 있다.
- 학습해야할 파라미터 수는 553*4 개 이다.
- 우선 Output Channel이 4이기 때문에 4개의 filter가 필요하다.
전체적인 Convolution Neural NetWork
ex) Conv - Pooling - Conv - Pooling - Fully Connected - Ouput Layer

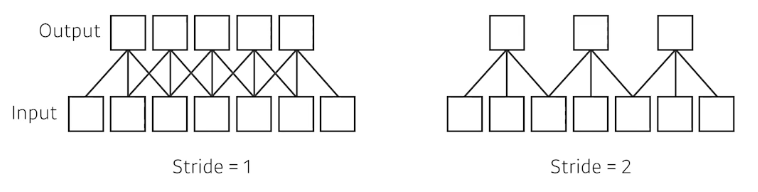
Stride
: (Step, 걷기) 내가 가진 filter를 가지고 얼마의 칸을 띄면서 찍을 것인지 → 얼마나 filter를 Dense, Parse하게 찍을 것인가
Padding
: 내가 가진 input image에 가장자리(Boundary)연산을 추가해주기 위해서 더 이어서 계산해주는 역할이다.
일반적으로 0 padding을 진행한다.

Parameter 개수 계산하기
: CNN 에서 네트워크 파라미터를 계산하는 것에 익숙해져야, 다른 모델들이 있을 때 모델을 읽어낼 수 있는 감을 얻을 수 있다고 하셨다.

1 * 1 Convolution의 의미
- Dimension Reduction
- Depth를 증가하지만 파라미터 수를 줄일 수 있다.(Bottleneck Architecture)

다양한 Convolution Net
: Depth 는 증가하고, Parameter는 감소하고, 성능은 증가하는! 과정을 주의깊게 본다.
AlexNet
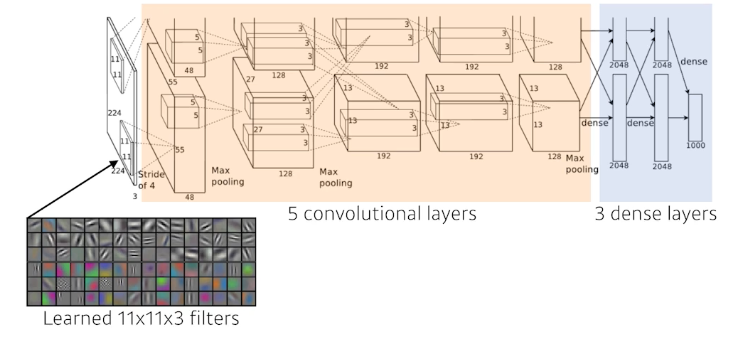
GPU가 부족해서 최대한 활용하기 위해서 두장의 GPU에 따로 훈련시키는 전략을 했다.
5개의 ConvolutionDayer와 3개의 Dense Layer로 구성되어 있다.
- Key Idea
- ReLU Activation Function을 적용
- 2개의 GPU를 사용
- Local response normalization, Overlapping Polling
- Data Augmentation
- Dropout
VGGNet

- Key Idea
- 3*3 Convolution Filter들을 적용
- 1*1 Convolution을 Fully-Connected Layer를 위해서 사용
- Dropout
- VGG16, VGG19
왜 3*3을 2번 사용하는 것이 이득인가?
→ 똑같은 Receptive Field이지만, 파라미터 수를 줄일 수 있기 때문이다.

GoogLeNet
: Network in Network 구조(NIN 구조라고 불린다.)

하나의 Inception Block을 살펴본다.

- 1 * 1 Convolution을 추가 하면서 파라미터 수를 줄일 수 있다. (중요)
- → 채널방향으로 Dimension을 줄이는 효과가 있다.
How?

Result : 대략 30%로 줄일 수 있다.
ResNet
: Neural Network는 깊어질 수록 Train하기가 어렵다.
Overfitting은 파라미터 수가 많을 수록 보통 발생한다. → ResNet은 identity map을 추가함으로써 이를 극복


- Conv - Batch Norm - Activation Function - Conv - Batch Norm 순서로 진행
1*1 Convolution을 추가하면서 Channel을 조절할 수 있다.
DenseNet
: Addition 대신에 Concatenation을 진행한다.
→ 문제는 Channel이 기하급수적으로 커진다. 그래서 Convolution feature map이 같이 커지니, 파라미터 수도 늘어난다. 그래서 중간에 1*1 Convolution을 통해서 파라미터 수를 줄인다.

Sumary
VGG : 3*3 을 반복한다.
GoogLeNet : 11 Convolution을 통해 *파라미터를 줄인다.**
RestNet : skip-connection으로 네트워크를 Deep하게 쌓을 수 있었다.
DenseNet : concatenation을 적용하면서 더 좋은 성능을 낼 수 있었다.
Semantic Segmentation
: 이미지 픽셀마다 분류하는 것(Hard)

기본적인 CNN 모델 같은 경우는 Conv→Fully Connected 구조였다.

여기서 Dense Layer를 없애고, Fully Convolution Network를 만들고 싶다는 아이디어.

그러면 파라미터 수를 계산해보자! 재밌는 점은 같다!

→ 이런 과정을 Convolutionalization이라고 한다.
그러면 왜 이런 Convolutionalization을 진행할까?
- Input Demension에 Independent하다. Output으로 Heat map으로 뽑아낼 수 있어 분류 모델을 만들어 낼 수 있다.(Semantic Segmantation 등등 가능)
- 우리가 Coarse Output을 만들고 싶다.(늘리는 과정이 필요하다.)

- Deconvolution : Convolution의 역은 아니지만, 파라미터 수, 네트워크 입출력을 봤을 때는 비슷하다.
Detection
: 이미지 안에서 패치를 뽑아내고 싶다.
R-CNN
과정
input image를 놓고 → 2000개 지역 뽑고(selective search) → 각각에 대해 Feature를 계산한다.(AlexNet) → SVM을 통해서 분류한다.

SPPNet
Bounding Box에 대해 CNN을 전부 통과시켜야했던 R-CNN의 문제를 해결하고 싶다.
→ 이미지 안에서 CNN을 한번만 돌리자.

Fast R-CNN
과정
- input에 대해 Bounding Box들을 구한다.
- Convolutional Feature map 생성
- 각각의 region에 대해 ROI pooling을 통해 고정된 길이의 Feature를 뽑는다.
- Neural Network를 통해 2가지 Output을 뽑아낸다.(Class & bounding-box regressor)

Region Proposal Network + Fast R-CNN

Region Proposal Network
: 이미지에서 특정 Boundary가 원하는 Target이 있을지 판단하는 역할
anchor Box를 통해서 판단한다. → anchor Box는 이미 고정된 사이즈의 Box이다.
여기서도 Fully-Connected Layer가 관여한다.

- 3개의 다른 region 크기
- 네개의 bounding box 파라미터(조정 가능)
- Box 가 의미가 있는지(2가지)
→ 예시에선 총 54개의 출력을 통해서 Boundary가 의미가 있는 지 판단할 수 있게 된다.
YOLO
: 극도록 빠른 Object Detection 알고리즘이다.
그냥 이미지 한장에서 찍어서 Output이 나오기 때문에 엄청 빠르다.
동시다발적으로 여러개의 Bounding Box들과 Class 확률을 예측한다.

→ 이미지가 들어오면, 내가 찾고 싶은 물체의 중앙이 Grid Cell에 들어가면 해당 물체의 Bounding Box와 해당 물체가 무엇인지 같이 예측하는 원리
(x,y,w,h)를 예측하고, 신뢰도를 측정한다.
또한 각각의 셀이 Class Probability를 예측한다.
이를 Tensor로 표현하면 다음과 같다.

[수업 회고]
- 기본적인 Convolution 연산이라는 것이 무엇인지 알게 되었다.
- CNN의 핵심인 Filter를 통해서 물체의 Feature를 파악하는 것이 핵심이라는 점을 알게 되었다.
- Padding, Stride 같이 아웃풋 크기를 조절하거나 정보를 더 손실없이 하기 위한 방법을 배웠다.
- 1*1 Convolution이 어떤 식으로 진행 되는 지, Output 채널을 줄이고 파라미터 수를 줄일 수 있는 장점 때문에 쓴다는 것을 알게 되었다.
- 여러가지 CV에 대한 예시들을 통해서 CNN기반의 모델들을 알게 되었다.
[피어 세션 정리]
- CNN 구조에 대해서 브리핑했다.
- 1 * 1 Convolution Layer의 필요성에 대해서 토론했다.
- 알고리즘 코드 리뷰
- Convolutionalization 의 필요성에 대해서 토론했다.