[08.18] Day12 - 👍 'PyTorch 구조'
[PyTorch] AutoGrad, Optimizer, Dataset, Dataloader
[수업 내용]
강사 : 최성철 교수님
논문을 구현할때 → 수많은 반복의 연속이다.
(Layer들을 블록처럼 쌓아서 다음으로 넘기는 구조. 그래서 하나의 블록을 정의하고 이것들을 연결해 Forward, BackPropagation 하는 과정)
블록 ⇒ torch.nn.Module
: 딥러닝을 구성하는 Layer의 base class이다.
Input, Output, Forward, Backward를 정의하면 된다. 학습의 대상이 되는 파라미터를 정의해야 한다.
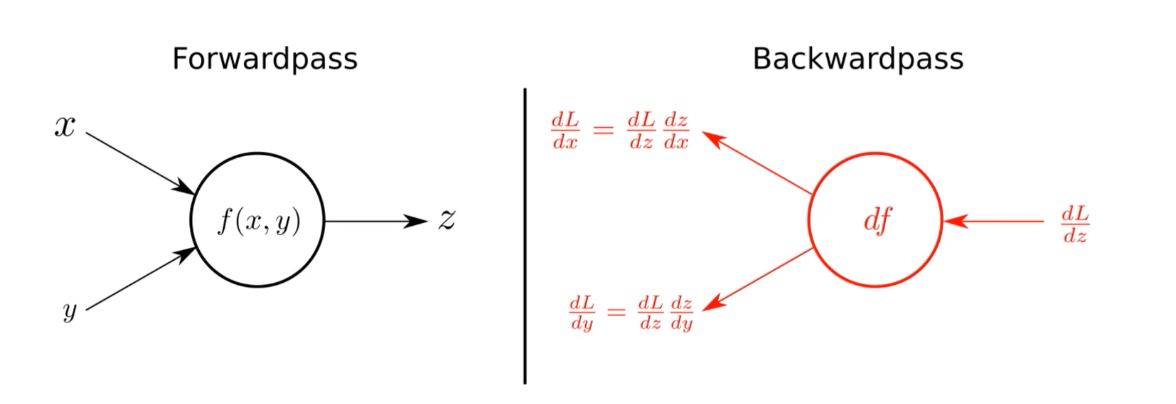
nn.Parameter 라고 하는 클래스에 Weight를 저장하고
Tensor 객체의 상속 객체이다. nn.Module 내에 attribute 가 될 때, required_grad = True 를 설정해야 AutoGrad의 대상이 된다.
Forward
class Linear(nn.Module):
def __init__(self, input, output, bias=True):
super().__init__()
self.input = input
self.output = output
self.weights = nn.Parameter(torch.randn(input, output))
#파라미터 정의 input, output 사이즈에 맞게 가중치 행렬을 만든다.
self.bias = nn.Parameter(torch.randn(output))
#bias 정의 output 사이즈에 맞게 bias 벡터를 정의한다.
def forward(self, x):
return x @ self.wieghts + self.bias
==============================
#Weights 보고 싶으면?
for param in 모델.parameters():
print(param)
#Tensor로 선언하면? => 방식은 거의 동일한다.
#하지만 파라미터를 보여주지 않는다.Backward
Layer에 있는 파라미터들의 미분을 수행한다.
Forward의 결과값과 실제값의 차이 → Loss에 대해 미분을 진행한다.
그리고 해당 값으로 파라미터를 업데이트 한다.
for epoch in range(epochs): #epoch마다 Update 진행된다.
optimizer.zero_grad() #optimizer를 초기화한다. 학습할때, gradient update가 업데이트 되기 때문에 이전이 영향을 주지 않게 하기 위해서
output = model(input)
loss = criterion(outputs, labels)
#criterion으로 loss값을 구함
loss.backward()
#Auto grad
optimizer.step()
#한번에 업데이트 된다.
criterion = torch.nn.MSELoss() #criterion이라는 loss 객체를 만듬
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) #optimizer종류를 고르고 파라미터와 학습량을 결정한다.보통은 Module에서 backward와 optimizer를 오버라이드해서 사용한다.
밑단부터 뜯어서 계산해보자!
class LinearModel(nn.Module):
def __init__(self, dim, lr,):
super(LR,self).__init__()
self.w =torch.zeros(dim, 1, dtype = torch.float).to(device)
self.b = torch.scalar_tensor(0).to(device)
self.grad = {'dw': torch.zeros(dim,1,dtype = torch.float).to(device),
'db' : torch.scalar_tensor(0).to(device_}
self.lr = lr.to(device)
#forawrd 과정
def forward(self, x):
z = torch.mm(self.w.T, w) + self.b #formula 정의
a = self.sigmoid(z) #activation function 적용
return
#sigmoid함수정의
def sigmoid(self, z):
return 1/(1+ torch.exp(-z))
#backward정의 -> 보통 AutoGrad지원
def backward(self, x, yhat, z):
self.grad['dw'] = (1/x.shape[1]) * torch.mm(x, (yhat-y).T)
self.grad['db'] = (1/x.shape[1]) * torch.sum(yhat-y)
#미분에 대한 업데이트 정의
def optimize(self):
self.w = self.w - self.lr * self.grad['dw']
self.b = self.b - self.lr * self.grad['db']
#loss function
def loss(yhat, y):
m = y.size()[1]
return -(1/m) * torch.sum(y*torch.log(yhat) + (1-y) * torch.log(1-yhat))
#prediction 하는 함수
def predict(yhat, y):
y_pred = torch.zeros(1, y.size()[1])
for i in range(yhat.size()[1]):
if yhat[0, i] <= 0.5:
y_pred[0,i] = 0
else:
y_pred[0,i] = 1
return 100 - torch.mean(torch.abs(y_pred -y)) * 100 결론 : 이런 과정들, 각 함수들을 PyTorch에서 제공해주니, 우리는 파라미터와 구조만 잘 맞춰서 조립하자!
DataLoad 와 Dataset
: PyTorch에서는 Dataset API를 제공하기 때문에 쉽게 데이터를 feeding 시켜줄 수 있다.
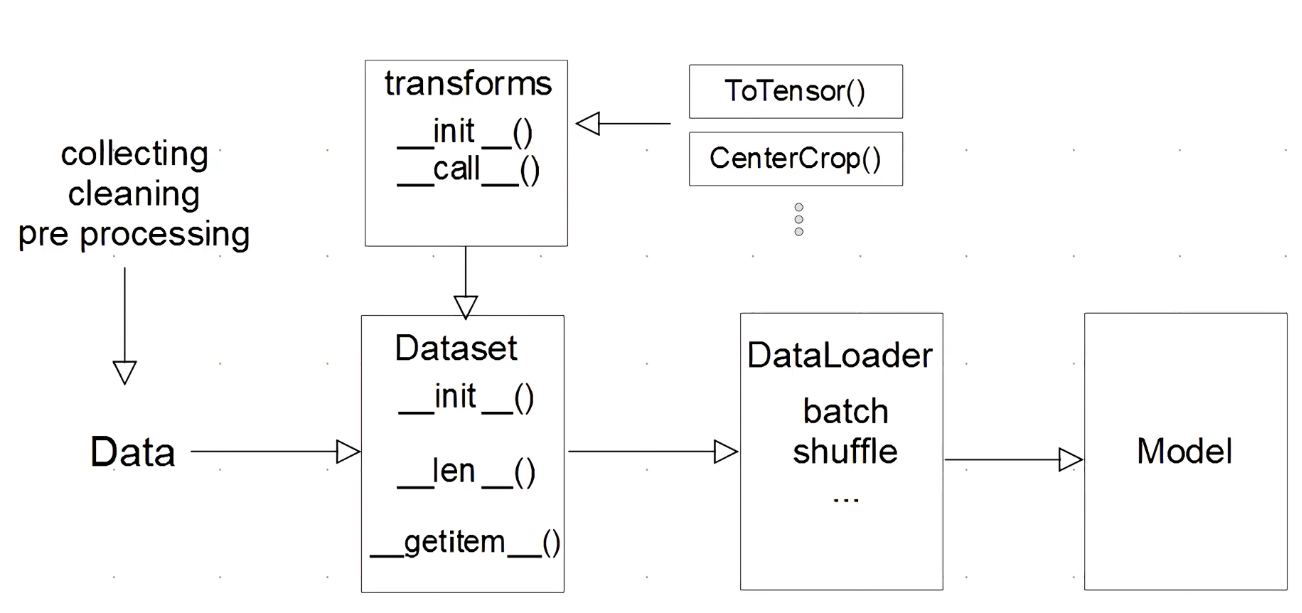
- 데이터를 모아서 폴더에 넣어놓는다.
- Dataset class 에서 여러개의 함수를 지원해준다.
- Transform은 전처리, 변형시에 처리해준다. 또한 Tensor로 바꿔준다.
- DataLoader는 데이터들을 모아서 feeding시켜준다. (batch를 만들거나, shuffle되어 들어간다.)
DataSet 클래스
: 데이터 입력 형태를 정의하는 클래스이다. 데이터를 입력하는 방식의 표준화
import torch
from torch.utils.data import Dataset
class CustomDataset(Dataset):
#초기 데이터 생성 방법 설정
def __init__(self, text, labels):
self.labels = labels
self.data = text
#데이터 전체 길이 return
def __len__(self):
return len(self.labels)
#idx 값을 주면 데이터 형태를 반환한다.
def __getitem__(self, idx):
label = self.labels[idx]
text = self.data[idx]
sample = {"Text" : text, "Class" : label}
return sample유의할 점
- 데이터 형태에 따라 각 함수를 다르게 정의한다.
- 모든 것을 데이터 생성 시점에 처리할 필요는 없다.
- 데이터 셋에 대한 표준화된 처리방법을 제공할 필요가 있다.
- 최근에는 HuggingFace 등 표준화된 라이브러리를 이용한다.
DataLoader 클래스
: Data의 배치를 생성해주는 클래스이다.
학습 직전 데이터 변환을 책임을 맡는다. Tensor로 변환 + Batch 처리가 메인 업무이다.
Loader = DataLoader(DataSet, batch_size= 묶을 크기, shuffle= True)
next(iter(Loader)
#Loader 같은 경우 iterable한 객체이기 때문에 호출하는 시점에 메모리에 올라가 처리가 된다.
#iter() -> Generator로 뽑아줌.
####DataLoader 클래스####
DataLoader(dataset, batch_size=1, shffle=False, smapler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, * , prefetch_factor=2,
persistent_workers=False)[수업 회고]
- forward 함수에서 layer와 선언한 변수들을 활용해서 하나씩 적용되는 모습이라는 것을 알았다.
- backward 같은 경우 .backward() 함수를 사용하면 자동적으로 gradient를 구할 수 있다는 것을 알았다, 또한 step() 함수도 optimize 하는 기능이라는 것도 알게 되었다.
- DataLoader와 DataSet의 각각의 기능에 대해서 알게 되었고, 과제를 통해 들어가는 파라미터들을 더 자세히 보게 되었다.
[피어세션 정리]
- 논문 자료들을 각각 나누고 멘토링때 이야기 해보기 전에 준비했다.
- Generator와 Iterator의 차이점을 공부했다.
- Python Generators: Memory-efficient programming tool
Python Generators: Memory-efficient programming tool
The idea behind writing this article was to provide a comprehensive understanding of the basics of generators which might take days to…
medium.com