-
[09.07] NLP - LSTM과 GRU네이버 부스트캠프 AI Tech 2기 2021. 9. 14. 14:40728x90반응형
이전 정리에서 더 진화한 Long Term Dependency를 고려한 모델들을 살펴본다.
LSTM
구조
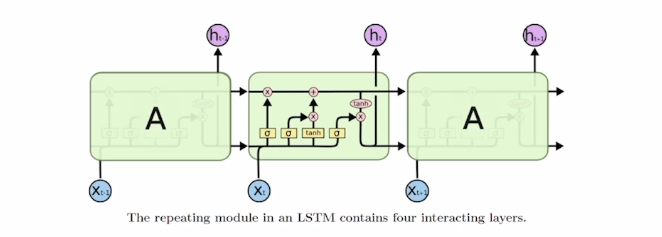
배경 : Long-Term Dependency 문제를 해결하고자 나왔다.
RNN이 가진, 매 Time마다 바뀌는 hidden state를 단기기억을 담당하는 기억 소자로 본다. 이 단기 기억을 Sequence가 시간이 지나면서 보다 길게 기억할 수 있도록 나온것이다.
이전, RNN에서는 입력으로 (Xt, ht-1) 두개가 들어갔지만, LSTM에서는 (Xt, ht-1, Ct-1) 이렇게 3개가 들어간다. Ct-1 이것을 우리는 Cell State Vector라고 부르고, ht-1은 hidden state Vector를 의미한다. 그리고 output으로는 (Ct, ht) 두개를 내주게 된다. Ct 가 좀 더 핵심적인 역할을 하는데, 정보를 담고 있고, ht-1은 이 Cell State Vector를 한번더 가공한 후, 해당 t 에서 노출할 필요가 있는 정보만을 남긴 Filtering 된 정보를 담는 Vector로 볼 수 있다.
조금 더 구체적으로 살펴보자.
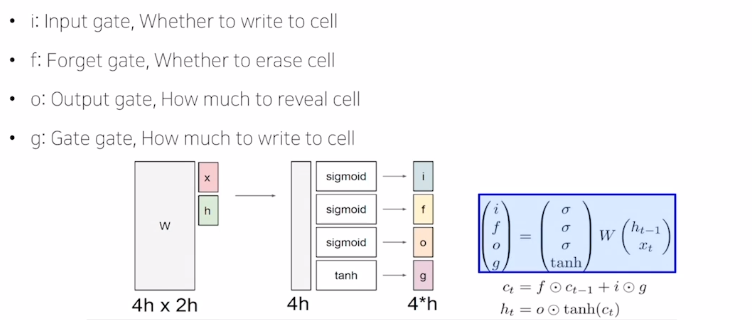
Xt와 ht-1이 전달이 되었을때, W(가중치) matrix와 연산을 하고나서 4 부분으로 쪼개서 각각의 해당하는 벡터에 Sigmoid와 tanh함수를 적용해서 non-linear function을 거치게 된다. 그리고 각각의 벡터는 Input, Forget, Output, Gate Gate 라고 분류한다.
그리고 이 Gate들을 사용해서 Cell State Vector를 계산할 수 있게 된다.
Input, Forget, Output Vector 같은 경우는, Sigmoid 함수를 거쳐나오기 때문에 0~1 사이의 값을 가지게 된다. 그리고 다른 Vector와 Element-Wise Multiplication을 통해서 곱해지는 벡터가 가지던 값을 각각 0~1 사이 그 값과 곱해주면서 원래 가지던 값(정보)에 일부만 가지도록 한다.
Gate Gate에 적용되는 tanh함수는 -1~1의 사이의 값을 가지고, 원래 RNN에서 선형 결합 후 tanh를 통해 최종적인 hidden state Vector를 구하는 것 처럼 현재 time step에서 유의미한 정보를 담는다고 볼 수 있다.
- Forget Gate
- 이 Gate 같은 경우, 위의 예시에서 f 값이 forget gate 값으로 볼 수 있는데, sigmoid 함수를 통과하기 때문에 0~1 사이 값과 Ct-1을 Element-Wise Multiplication을 하게 되니, 값이 작아질 수 밖에 없고 이는 이전에 정보를 조금 잊어버리는 역할을 수행한다고 보기 때문에 Forget Gate라고 불린다.

- 이 Gate 같은 경우, 위의 예시에서 f 값이 forget gate 값으로 볼 수 있는데, sigmoid 함수를 통과하기 때문에 0~1 사이 값과 Ct-1을 Element-Wise Multiplication을 하게 되니, 값이 작아질 수 밖에 없고 이는 이전에 정보를 조금 잊어버리는 역할을 수행한다고 보기 때문에 Forget Gate라고 불린다.
- Gate Gate, Input Gate
- Gate Gate 같은 경우 tanh 함수를 거쳐서 나오고, Input Gate 값은 Sigmoid 함수를 거쳐서 나오게 된다. 최종적으로 현재 Step에서 Cell State를 구하기 위해서 Input Gate의 벡터와 Gate Gate 벡터의 Element Wise 곱한 값과 이전 forget Gate와 이전 Cell State Vector를 Element Wise 곱한 벡터와 덧셈 연산이 적용된다. 여기서 Input Gate와 곱해주는 이유는, 예를 들어 한번의 선형 변환으로 Ct-1의 더해줄 정보를 만들기 어려운 경우, 더해주고자 하는 큰 값들로 구성된 C틸다(Gate Gate값)의 형태로 만들어 준 후, 전부 담아주는 것이 아니라 Ct-1와 맞춰주기 위해서 조금 덜어내는 역할을 한다.

- Gate Gate 같은 경우 tanh 함수를 거쳐서 나오고, Input Gate 값은 Sigmoid 함수를 거쳐서 나오게 된다. 최종적으로 현재 Step에서 Cell State를 구하기 위해서 Input Gate의 벡터와 Gate Gate 벡터의 Element Wise 곱한 값과 이전 forget Gate와 이전 Cell State Vector를 Element Wise 곱한 벡터와 덧셈 연산이 적용된다. 여기서 Input Gate와 곱해주는 이유는, 예를 들어 한번의 선형 변환으로 Ct-1의 더해줄 정보를 만들기 어려운 경우, 더해주고자 하는 큰 값들로 구성된 C틸다(Gate Gate값)의 형태로 만들어 준 후, 전부 담아주는 것이 아니라 Ct-1와 맞춰주기 위해서 조금 덜어내는 역할을 한다.
- Output Gate
- 먼저, Ct에 tanh를 적용해서 RNN과 같이 -1~1사이 값을 가지는 벡터를 가지도록 한다. 그리고 앞서 나온 Output Gate의 값과 Element-Wise 곱을 수행해서 현재 hidden state Vector를 구하게 된다.

- 먼저, Ct에 tanh를 적용해서 RNN과 같이 -1~1사이 값을 가지는 벡터를 가지도록 한다. 그리고 앞서 나온 Output Gate의 값과 Element-Wise 곱을 수행해서 현재 hidden state Vector를 구하게 된다.
- Ct → 기억해야할 모든 정보를 담고 있는 Vector
- ht → 현재 timestep에서 예측값을 내는 OutputLayer의 입력으로 사용되는 Vector(해당 Timestep에 필요한 직접적인 정보를 담는다.)
GRU
: LSTM의 모델을 경량화(Gate를 줄여서)하고 빠른 계산 시간을 위해서 만들게 되었다.

가장 큰 특징은 Cell State Vector와 Hidden State Vector를 하나로 일원화해서 ht-1로 처리한다. 전체적인 동작은 LSTM과 굉장히 비슷하다. 재밌는 점은 Forget Gate를 GRU에서는 Input Gate하나로 처리한다.(zt → Input Gate에 해당하는 값) 즉, Input Gate가 커지면 Forget Gate에 해당하는 값이 작아지게 된다.

ht-1와 ht 틸다 두개의 정보간에 가중 평균(h 틸다를 적용해서)을 내는 것으로 볼 수 있다. (이유는 zt 에서의 값과 zt-1에서의 값은 서로 맞는 노드끼리 더했을 때 항상 1이 되도록 하는 성질을 가지기 때문이다.)
Backpropagation
정보를 담는 주된 Vector, Cell State Vector가 업데이트 되는 과정이 RNN에서 Whh라는 행렬을 계속적으로 곱해주는 연산이 아니라 전 Time Step의 Cell State Vector을 구할때, Forget Gate를 통해서 각각의 Step별로 연산이 진행되고, 곱셈이 아니라 덧셈을 통해서 진행되기 때문에 Vanishing 문제를 해결했다고 볼 수 있다.
반응형'네이버 부스트캠프 AI Tech 2기' 카테고리의 다른 글
[09.08] NLP - Beam Search & BLEU Score (0) 2021.09.14 [09.08] NLP - ⭐️ Sequence To Sequence with "Attention" (0) 2021.09.14 [09.07] NLP - Recurrent Neural Network(RNN) & Language Modeling (0) 2021.09.14 [09.06] NLP - Bag of Words & Word Embedding (0) 2021.09.14 🏃 Mask Image Classification [P Stage Wrap up 개별 리포트] (2) 2021.09.06 - Forget Gate