-
[09.08] NLP - Beam Search & BLEU Score네이버 부스트캠프 AI Tech 2기 2021. 9. 14. 14:54728x90반응형
Beam Search
Seq2Seq 같은 자연어 생성 모델에서 테스트 타임에서 좀 더 좋은 생성 결과를 얻을 수 있는 Beam Search라는 것이 있다.
Sequence로서 전체적인 확률값을 보는 것이 아니라 현재 타임에서 가장 좋은 확률을 가지는 단어를 선택하는 Greedy Decoding 방식을 보통 따른다. 그러나 이런 Greedy Decoding 방식에서 만일 잘못된 예측을 한 경우에 뒤로 올아갈 수 없는 문제가 있다. 이를 어떻게 해결할까??

입력되는 문장을 x라고 하고 출력되는 문장이 y라고 할때, 각각 x가 들어올때, 예측되는 첫번째 단어 y1.. y1과 x가 들어올때, 예측되는 y2단어의 확률 값을 곱하는 식으로 P(y|x) 라는 joint Probability, 동시사건에 대한 확률 분포를 수식으로 적을 수 있게 된다.
Step t마다 가능한 모든 경우를 다 따진다면, 그 경우는 매 Step마다 고를 수 있는 단어의 Size가 되고 그것을 V라고 하면, V^t 으로 모든 가지수를 따져야 한다. O(V^t)의 시간복잡도를 구할 수 있는데 이를 다 따지는 것은 너무 현실적으로 불가능하다.
그래서 차선책이 Beam Search이다.
이는 Greedy Decoding과 모든 경우를 따지는 상황의 중간 방법으로 볼 수 있다.
아이디어 : 각각의 Step 마다 하나의 단어만을 고려하는 것도 아니고, 모든 조합을 고려하는 것도 아니고 정의해놓은 k개의 가능한 가지수를 고려하고 Step이 진행되면서 k 가 유지되면서 최종적으로 나온 Candidate들 중에서 가장 확률이 높은 것을 선택하는 방식이다.

k : Beam Size라고 정의한다 (보통 5~10정도로 설정한다.)
우리가 최대화 하고 싶은 것은 PLM으로 위의 Joint Probability를 의미한다. 여기에 Log를 붙이게 되면 덧셈 연산으로 식이 변경된다.

Beam Size가 2라면 Greedy Search와는 다르게 2개의 가장 확률값이 높은 것들을 골라서 조건부 확률을 고려한다. Greedy라면 한개만 고려할 것이다. 위에 예시는 I 와 he가 뽑힌 것을 볼 수 있다.
음수가 나오는 이유는 확률은 0~1 사이 값이기 때문에 로그 그래프에서 보면 음수가 나오는 것이다. 물론 음수지만 확률값이 크면 음수도 커지기 때문에 값이 클 수록 더 확률이 크다고 볼 수 있게된다.

2개의 he, I에 대해서 각각의 경우에 대해서 다음 단어를 예측하도록 한다. 각각의 k 개에 대해서 k개를 고려하기 때문에 총 k^2개를 고려한다. 위의 상황에서 k^2개의 결과들 중에서 확률이 가장큰 -1.7, -1.6이 높다고 볼 수 있는데 왜 이러냐면 다시 k개의 candidate로 추리는 과정을 거치게 되는 것이 Beam Search 의 알고리즘이기 때문이다.

지금 우리는 다음에 hit, was 를 따라가는 2개의 가설을 따라가고 다음 단어를 예측하는 과정에서 각각의 단어의 k개를 고려하고 k^2개 중에서 다시 k개를 고르게 된다.

최종적으로 'a,' 'me' 이렇게 나오게 되고 이과정을 다시 반복적으로 수행해서 Decoding 과정을 진행하게 된다.
- Greedy Decoding : token이 나오면 Decoding 끝!
- Beam Search Decoding : 여러 가정들이 존재하고 각각 다른 시점에서 token을 생성하게 되는데, 어떤 가설이 를 생성했다 싶으면 더이상 생성은 안한다. 그리고 그 값을 임시 저장공간에 저장을 하고 나머지 가설들에 대해서 Decoding을 해서 똑같이 진행해서 예측 값을 임시 저장공간에 저장한다. T라는 timestep의 최대값이 있는데 거기까지 진행해서 중단하거나 임시 저장공간에 있는 값들의 가설들이 n 개 만큼에 진행이 되었다면 종료시킨다. 완료된 가설들의 list를 얻게 되고 그 중 가장 큰 하나의 값을 뽑아야 한다. 그 값을 최종적으로 예측 값이라고 생각해서 전달한다. (긴 가설일때 보통 lower 한 score를 가지게 되는데 → 이는 단어가 순차적으로 생성되면서 동시 사건 확률을 고려하고 매 단어를 생성할 때마다 log 값들이 더해진다 그래서 가설이 길면 그만큼 더해지는 값(음수)이 많아지니 작은 값일 것이다.) 그래서 이를 위해 길이를 Normalize 하는 과정을 한번더 거친다.

BLEU Score
: 자연어 생성 모델의 품질, 정확도를 측정하는 Score이다.
우리가 말을 할때, "내가 너를 사랑하나봐."라는 말과 "음 내가 너를 사랑하나봐."라는 문장은 비슷한 의미를 가지고 있지만, 위의 Score들로 계산하면 위치에 기반하기 때문에 "음 - 내가", "내가 - 너를" 이렇게 Ground Truth와 맞지 않는 상황이 생긴다. 이러면 모델의 정확도가 0%라고 판단할 것이다. 그래서 Ground Truth 전체를 기반으로 해서 Sequence 문장을 평가해야한다.

(Precision, Recall(재현율), F-Score)
- Precision(정밀도) : (Ground Truth 문장에 겹치는 것들 개수 / 예측한 문장의 길이의 단어 수) → 로 계산이 진행이 된다. ⇒ 예측된 결과가 노출될때 우리가 느끼는 정확도
- Recall(재현율) : (Ground Truth 문장에 겹치는 것들 개수 / 참조하는 문장의 길이의 단어 수) → 로 계산이 된다. ⇒ 원하는 정보에 부합하는 것들의 개수에서 얼마나 우리가 원하는 정보를 노출시켜 주었는가
- F-measure : 위의 두개의 지표를 통합적으로 보여주기 위한 지표, 3가지 평균 방법이 있는데, 산술평균, 기하평균, 조화평균 중 조화평균은 작은 값에 조금더 가중치를 부여하는 평균 산출 방법이다. F-measure는 바로 조화 평균을 택한 방식이다. 그래서 Precision, Recall을 요약할때 작은 값에 조금 더 치중해서 계산을 하도록 도와준다.


다음 예시를 보면 두개의 모델에서 정확도, 재현율, F-measure를 계산했을때, model2 같은 경우 문법적을 전혀 맞지 않지만 모두 100%를 보여준다. 오히려 model1에서 예측한 것이 더 정확하다고 볼 수 있다. 자연어에서는 이런 문제들이 발생하기 때문에 이를 보완하기 위해서 BLEU Score 를 계산한다.
BLEU Score
: 개별 단어로 봤을 때, Ground Truth와 얼마나 공통적인 단어가 나왔는가? 에다가 N-gram이라고 하는 연속된 N개의 단어로 봤을 때, Ground Truth와 얼마나 겹치는 지 판단해서 계산이 진행된다.
보통 1 ~ 4의 크기의 N-Gram의 Precision만 고려한다.
Brevity penalty 라고 하는 항을 통해서 예측한 길이가 Ground Truth 문장의 길이보다 크게 되면 1이라는 값을 가지게 하고 짧다면 작은 값을 가지게 함으로써 Precision 값을 낮춰주겠다는 의미이다.
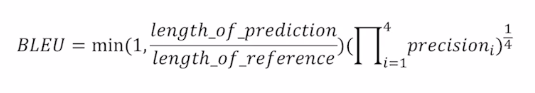
→ 기하 평균을 내주는데, 이는 산술평균이 아닌 조금더 낮은 값에 많은 가중치를 부여한 형태로 평균 값을 계산하겠다는 의미이다. (조화 평균을 쓰지 않은 이유는 작은 값에 지나치게 가중치를 주기 때문)
아래 예시는 직접 손으로 해보자!😊
 반응형
반응형'네이버 부스트캠프 AI Tech 2기' 카테고리의 다른 글
[09.08] NLP - ⭐️ Sequence To Sequence with "Attention" (0) 2021.09.14 [09.07] NLP - LSTM과 GRU (0) 2021.09.14 [09.07] NLP - Recurrent Neural Network(RNN) & Language Modeling (0) 2021.09.14 [09.06] NLP - Bag of Words & Word Embedding (0) 2021.09.14 🏃 Mask Image Classification [P Stage Wrap up 개별 리포트] (2) 2021.09.06